无
”外汇 招行 python 爬虫“ 的搜索结果
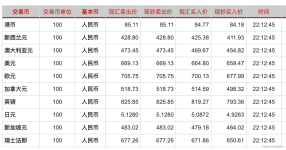
访问网站http://fx.cmbchina.com/hq/ 可以看到招商银行当天的外汇汇率, 本项目的任务是 编写一个爬虫程序爬取这些外汇的 数据并存储到数据库 。
手把手教你入门Python爬虫 前言 在上一篇文章中,我们讲解到了基础的计算机网络知识,并完成了“爬取豆瓣Top250电影信息”的项目。那么这一次,作者将带领大家完成“爬取中国银行外汇牌价”项目。 1. 观察网站,...

BeautifulSoup有五种基本元素,分别是标签(Tag),标签名(Name),标签的属性(Attribute),标签内非属性字符串(NavigableString)以及标签内的注释部分(Comment)。理解好BeautifulSoup库的五种基本元素是使用...
一、思路分析 ...使用pyarm中的flask框架搭建可视化平台,使用sqlite数据库的数据制作简单的网页,并制作折线图、柱状图、散点图等等。 二、数据爬取 1.引入库 代码如下: from bs4 import BeautifulSoup ...
Python网络爬虫程序技术是使用Python编程语言来开发网络爬虫程序的技术。网络爬虫是一种自动化程序,可以通过互联网收集数据,并将其存储在本地计算机或数据库中,以供后续分析和处理。Python网络爬虫程序技术主要...
项目仓库 ...开发者: sunhailin-Leo ...获取中国银行外汇牌价的汇率(本项目模板以港币为Base) 获取时间可以自定义(设置起始时间不建议跨度太长) 爬虫数据支持存储在MySQL、MongoDB和CSV中(通过cmdline_start_spi...
和我们平时手动上网寻找信息一样,使用python爬虫主要由以下几个步骤。 一、打开网页。 我们需要使用python自带的urlopen的方法得到网页的反馈信息对象response,然后通过response对象的read方法...
为了解决这些问题,本篇使用爬虫爬取,pandas整理数据后存入数据库。 二、实现 STEP1爬取第一批数据 打开网站,输入在允许范围内的日期,点击查询,就发送了一个POST请求 F12打开开发者工具刷新后,可以看到这...
网络爬虫(又称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。 前言 最近接到了个爬取一些网站积分商品数据的需求,学习了一下爬虫的知识。为了避免以后忘记,特写一篇...

我们选择较为权威的‘中华英才网’,编写python爬虫获取该网站上的各个招聘信息说给出的工资,再取其行业工资的平均值,即为该行业目前的大概工资。 1 以深圳为例 如‘数据挖掘’这个职业在深圳查找的情况...

用python爬取数据进行汇率转换背景python脚本结语 背景 在工作中处理数据需求的时候遇到需要汇率转换的情况, 因此百度了一下, 找到了爬取数据的方法, 根据实际需求对原脚本进行了一下优化, 给大家分享一下, 复制即可...
window.title('招商银行外汇数据') window.geometry('450x300') tk.Label(window, text='货币种类').grid(row=0, column=0) tk.Label(window, text='现汇卖出价').grid(row=0, column=1) tk.Label(window, text...


# -*- coding: utf-8 -*- import requests import pandas as pd from lxml import etree import time from time import sleep url = '...headers={'User-Agent':'Mozilla/5.0 (Wi...
通过Python批量爬取银行网页的数据,主要爬取的是表格中的数据,此外还有图片,PDF文本的批量下载,网页地址的批量下载

整理了十大Python语言实用技巧,看看你会几个?
import requests from lxml import etree import pandas as pd from sqlalchemy import create_engine import time import random ...connect=create_engine('mysql+pymysql://user:password@xx:xx/xx?...
import requests from lxml import etree import os import sys from urllib.parse import quote # 对汉字进行URL编码,URL编码的方式是把需要编码的字符转化为 %xx 的形式 import tkinter as tk ...
推荐文章
- C++语法基础--标准库类型--bitset-程序员宅基地
- [C++] 第三方线程池库BS::thread_pool介绍和使用-程序员宅基地
- 如何使用openssl dgst生成哈希、签名、验签-程序员宅基地
- ios---剪裁圆形图片方法_ios软件圆形剪裁-程序员宅基地
- No module named 'matplotlib.finance'及name 'candlestick_ochl' is not defined强力解决办法-程序员宅基地
- 基于java快递代取计算机毕业设计源码+系统+lw文档+mysql数据库+调试部署_快递企业涉及到的计算机语言-程序员宅基地
- RedisTemplate与zset redis_redistemplate zset-程序员宅基地
- 服务器虚拟化培训计划,vmware虚拟机使用培训(一)概要.ppt-程序员宅基地
- application/x-www-form-urlencoded方式对post请求传参-程序员宅基地
- 网络安全常见十大漏洞总结(原理、危害、防御)-程序员宅基地